동기 부여
지금까지 text-to-image 생성 모델인 Latent Diffusion Model을 여러 개 다듬었지만, 이미지 생성 모델에 대한 논문을 다시 읽어보니 CFG 부분을 전혀 고려하지 않았다는 것을 깨달았습니다. 이를 염두에 두고 새로운 기법을 적용하고 다듬어 보았는데 그 결과가 상당히 흥미로워서 이 글을 쓰게 되었습니다.
텍스트 조건화의 중요성
텍스트 컨디셔닝은 텍스트-이미지 생성 모델에서 매우 중요한 역할을 합니다. 원하는 이미지를 출력하려면 프롬프트와 샘플을 정확하게 이해해야 하기 때문입니다.
Stable Diffusion에서는 샘플링 과정에서 텍스트 조건을 적용하여 샘플의 품질을 향상시키기 위해 다양성을 줄이고 classifier-free 가이드를 적용하여 실제로 큰 효과를 보이는 원하는 이미지를 얻었습니다.
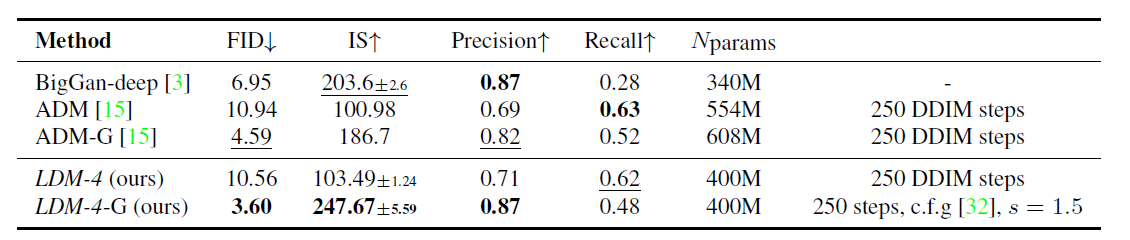
작업 테이블의 끝에서 LDM-4-G(CFG가 포함된 모델)에서 FID 및 정밀도 값이 훨씬 더 우수함을 알 수 있습니다. 그리고 다양성이 떨어지고 인지도가 떨어졌다.
분류자 지침이란 무엇입니까?
지금 살펴볼 개념인 분류기 없는 안내에 대해 알아보기 위해서는 먼저 분류자 안내가 무엇인지 알아야 합니다.
확산 모델이 등장하기 전에 이전에 사용된 GAN 생성 모델은 절단 또는 저온 샘플링을 통해 다양성을 줄임으로써 샘플 품질을 향상시켰습니다. 그러나 이러한 기법들은 확산 모델에서는 효과적이지 않았으며, 확산 모델이 GAN보다 성능이 좋지 않은 것으로 가정하였다.
Classifier Guidance는 조건부 확산 모델의 사후 학습 과정에서 샘플의 다양성과 정확도의 균형을 맞추기 위한 방법으로, 샘플링 과정의 점수(음의 대수 우도 함수의 1차 미분)와 이미지의 기울기를 결합합니다. 기존 함수 뒤에 그라디언트를 생성하는 분류자 로그 확률 보조 분류기 모델을 추가했습니다.
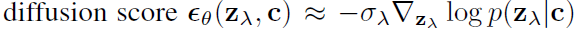
위의 함수에서 $z_{\lambda}$는 노이즈가 추가된 데이터를 의미합니다.
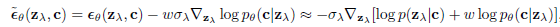
이와 같이 분류기를 이용하여 가이드를 제시함으로써 보다 양질의 사진을 얻을 수 있다.
그러나 분류기 안내를 사용하기 위해서는 클래스에 대한 레이블이 필요하고 분류기를 별도로 학습해야 한다는 큰 단점이 있다.
분류자 무료 안내란 무엇입니까?
분류기가 없는 확산 가이드 논문에는 Classifier Guidance가 있습니다. 노이즈 레벨에 따른 분류기는 별도로 학습시켜야 하며, 분류기를 기반으로 모델을 평가하는 수치인 IS와 FID를 높이는 것은 적대적 공격이라는 주장이다.
따라서 연구원들은 모델 자체에서만 작동하는 매우 간단하고 효과적인 방법인 분류기 없는 안내를 도입했습니다.학습 코드 한 줄만 바꾸면 바로 적용할 수 있어 방법이 매우 간단하다.
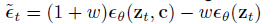
위 식에서 $\epsilon_{\theta}(z_{t},c)$는 텍스트 조건 $c$에 조건부이고 $\epsilon_{\theta}(z_{t})$는 무조건부입니다.
$w$에 대해 이 식을 재정렬하면 $$(1+w)\epsilon _{\theta }(z_{t},c)-w\epsilon _{\theta }(z_{t}) = w(\ 엡실론 _{ \theta }(z_{t},c)-\epsilon _{\theta }(z_{t}))+\epsilon _{\theta }(z_{t},c)$$
위의 방정식을 보면 이 방법에서 지침이 어떻게 작동하는지 직관적으로 이해할 수 있습니다. 이는 표본의 조건부 확률에서 무조건부 확률을 뺀 값을 증가시키는 단순한 구조 때문이다.
미세 조정과의 관련성
위에서 설명한 대로 분류자 없는 지침을 적용합니다. 조건부 확률에서 무조건부 확률을 빼야 하므로 무조건부 경우도 학습해야 한다. 지금까지 CFG를 고려하지 않고 무조건적인 경우는 학습되지 않았습니다. 그럼에도 불구하고 학습결과에 치명적인 악영향을 느끼지는 못했으나 classfier-free 지도를 적용하기 위해서는 텍스트 조건 없이도 공부가 필요하다.
따라서 학습 데이터셋에서 일부 이미지의 자막을 임의로 비우는 자막 드롭아웃 기능이 있는 미세 조정 저장소를 사용하는 것이 좋습니다.
또한 자막 포기율(자막이 데이터 세트에서 비어 있는 비율)에 대해 0.1(10%)을 권장합니다. 왜 0.1인지는 모르겠지만 학습할 때 0.1이 기본값인 것 같습니다. 참고로 너무 많이 올리면 학습이 잘 되지 않았습니다. B. 학습한 캐릭터와의 유사성이 떨어진다.
분류기가 없는 리더십을 위해 세 가지 모델 모두에 대해 10% 확률로 텍스트 삽입을 무효화하여 무조건적으로 훈련합니다. 우리는 4억 6천만 개의 이미지-텍스트 쌍이 있는 내부 데이터 세트와 4억 개의 이미지-텍스트 쌍이 있는 공개적으로 사용 가능한 Laion 데이터 세트(61)의 조합을 학습합니다. – Imagen 논문에서 언급됨
Imagen 기사에 따르면 Imagen 모델도 자막 드롭아웃을 10% 비율로 적용했습니다.
Caption Dropout을 실제로 사용하면서 학습한 결과 CFG 점수에 따라 다양성이 증가하는 것을 경험했습니다.
그리고 적용 전에는 CFG 값이 15 이상으로 증가하면 이미지가 완전히 망가졌지만 적용 후에는 값이 20으로 증가해도 문제가 없었다.
이 방법은 배울 수업이 여러 개일 때 더 도움이 될 것 같습니다.
이 기능을 지원하는 저장소는 다음과 같습니다. kohya-ss~에서 SD 스크립트그리고 빅터챌~에서 모든 Dream2trainer있다
참조
분류기 없는 확산 가이드 / https://arxiv.org/abs/2207.12598
이미지 합성에서 확산 모델이 GAN을 능가/ https://arxiv.org/abs/2105.05233
다음 딥러닝 글에서는 너무 어둡거나 너무 밝은 이미지가 미세 조정 시 학습되지 않는 이유와 해결 방법에 대해 쓰고자 합니다.