Stable Diffusion이 Creation 커뮤니티에서 매우 뜨거워지고 있습니다.
생성 AI의 발전은 빠른 속도로 이루어지고 있습니다.
그 중 하나는 텍스트 반전입니다.
아래는 논문에 게재될 공식 명칭입니다.
그림은 단어를 말합니다: 텍스트 반전을 통한 텍스트-이미지 생성 개인화
목표는 개인화된 텍스트-이미지 텍스트 반전을 만드는 것입니다.
나는 여기서 기존 잠재 확산 모델을 사용했다고 언급했습니다.
사전 훈련된 텍스트-이미지 모델(잠재 확산 모델)의 임베딩 공간에서 새로운 “단어”를 사용하여 개인 개체 또는 예술적 스타일과 같은 특정 개념을 생성하는 방법을 학습한다고 합니다. 그리고 이 새로 만들어진 새로운 “단어”를 사용하면 다른 문장에서도 사용할 수 있습니다.
아래는 S* objectified라는 새로운 단어입니다.
가장 왼쪽에 있는 3-4개의 샘플 이미지는 S*입니다.
이 개체 S*를 기존 텍스트에 붙여넣어 사진을 구성하는 것과 같이 생각할 수 있습니다.
아래 Elmo와 S*의 합성 이미지를 보면 Elmo 포즈가 S*가 하고 있는 포즈를 취하고 있는 것 맞죠?

아래 이미지는 간달프와 고양이의 합성 이미지로도 보여집니다.
텍스트 반전은 Stable Diffusion의 나머지 구성 요소를 변경하지 않고 그대로 두면서 새 텍스트 토큰에 대한 토큰 임베딩을 학습하여 작동합니다.

아래 사진의 물체가 무엇인지 모르겠습니다. 하지만 S*라는 왼쪽 입력 샘플을 학습하여 기존 스포츠카나 레고를 S* 객관화한 이미지입니다.

작업 모델의 구조는 다음과 같습니다.
대부분의 텍스트-이미지 변환 모델과 마찬가지로 텍스트 반전은 텍스트 인코딩 단계의 첫 번째 단계를 수행하여 프롬프트를 숫자 표현으로 변환합니다. 이것은 일반적으로 모델 사전의 항목에 해당하는 각 토큰과 함께 단어를 토큰으로 변환하여 수행됩니다.
그런 다음 이러한 항목은 특정 토큰의 연속적인 벡터 표현인 “임베디드”로 바뀝니다. 이러한 임베드는 일반적으로 교육 프로세스의 일부로 학습됩니다. 텍스트 반전은 또한 특정 사용자 제공 시각적 개념을 나타내는 새로운 임베드를 찾습니다. 그런 다음 이러한 임베딩은 다른 단어와 마찬가지로 새 문장에 통합될 수 있는 새 의사 단어에 연결됩니다. 어떤 의미에서 우리는 고정된 모델의 텍스트 임베딩 공간으로 반전을 수행하고 있습니다. 이 프로세스를 “텍스트 반전”이라고 합니다.
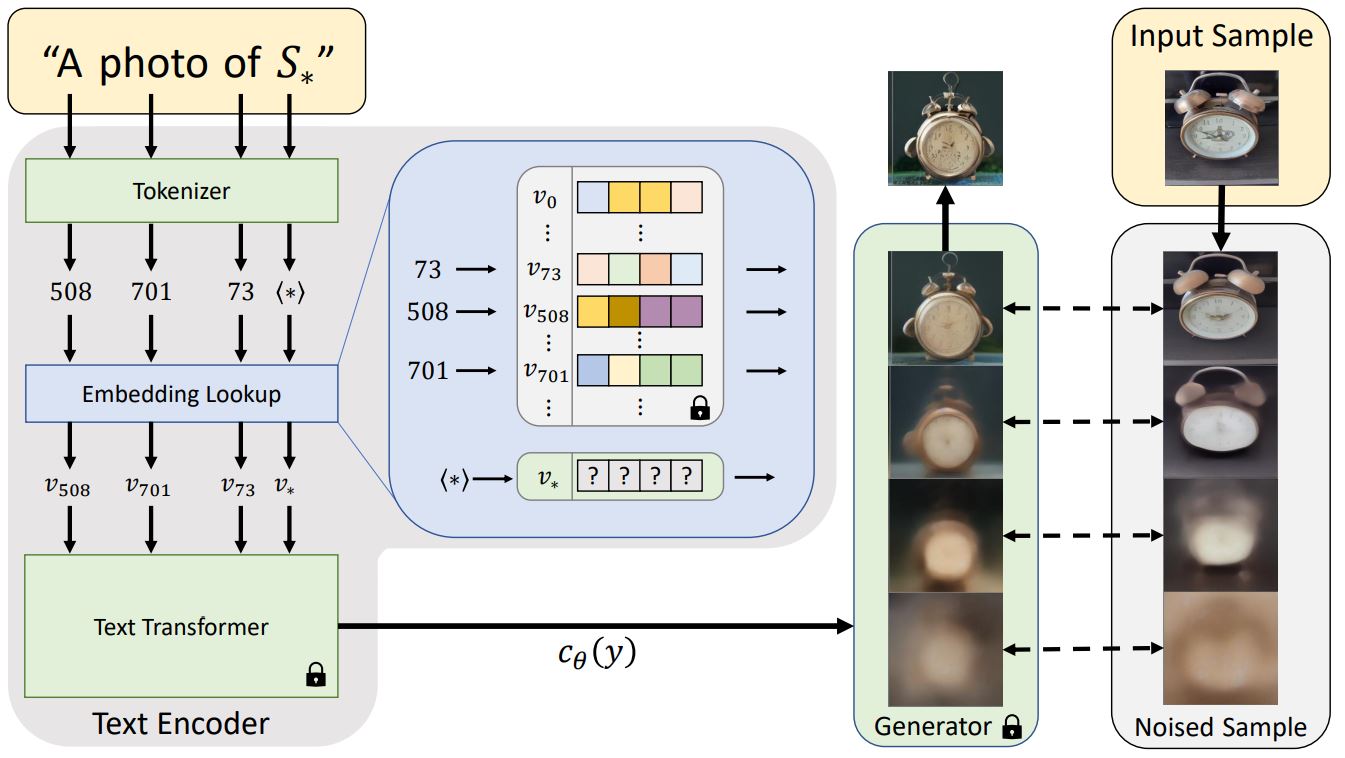
간단히 말해서 새로운 객체 S*도 훈련됩니다.
S*의 속성을 배우고 S*로 만드십시오.
그리고 S*를 문장에 함께 넣으면 AI가 S*가 포함된 문장의 문맥을 형성합니다.
이미지를 만들 때 텍스트의 S*도 영향을 미칩니다.
보시면 될 것 같습니다.
여기에도 문제가 있습니다.
모든 인공 지능 모델에는 편향이 있습니다.
텍스트-이미지 모델에도 동일하게 적용됩니다.
텍스트-이미지 모델은 학습 데이터에서 상속된 편향으로 인해 어려움을 겪을 수 있습니다. 새로운 개념을 배우는 대신 “편향된” 개념에 대한 새로운 임베드를 찾을 수 있습니다. 이러한 임베드는 작은 데이터 세트에서 찾을 수 있으므로 데이터를 보다 쉽게 큐레이팅하고 보다 공정한 표현을 보장할 수 있습니다.
왼쪽의 기본 모델에서 Doctor라고 하면 데이터셋이 너무 작아서 제대로 빌드가 되지 않는 것을 볼 수 있습니다.
따라서 S*로 의사 데이터를 추가로 학습하고 S*로 실제 의사를 만들 수 있습니다.
오른쪽은 Doctor라는 글자를 쓰지 않고 S*로 훈련된 Doctor를 만들어서 이미지가 훨씬 잘 나왔죠?

그리고 원하는 대상 이미지만 마스킹하여 이미지 생성에 도움을 줄 수 있습니다.

이것이 당신에게 많은 도움이 되기를 바랍니다.
https://textual-inversion.github.io/
그림은 단어를 말합니다: 텍스트 반전을 통한 텍스트-이미지 생성 개인화
텍스트-이미지 모델은 학습 데이터에서 상속된 편향으로 인해 어려움을 겪습니다. 새로운 개념을 배우는 대신 “편향된” 개념에 대한 새로운 임베딩을 찾을 수 있습니다. 이들은 작은 데이터 세트를 사용하여 발견되므로 데이터를 쉽게 큐레이팅하고 보다 공정한 표현을 보장할 수 있습니다.
textual-inversion.github.io